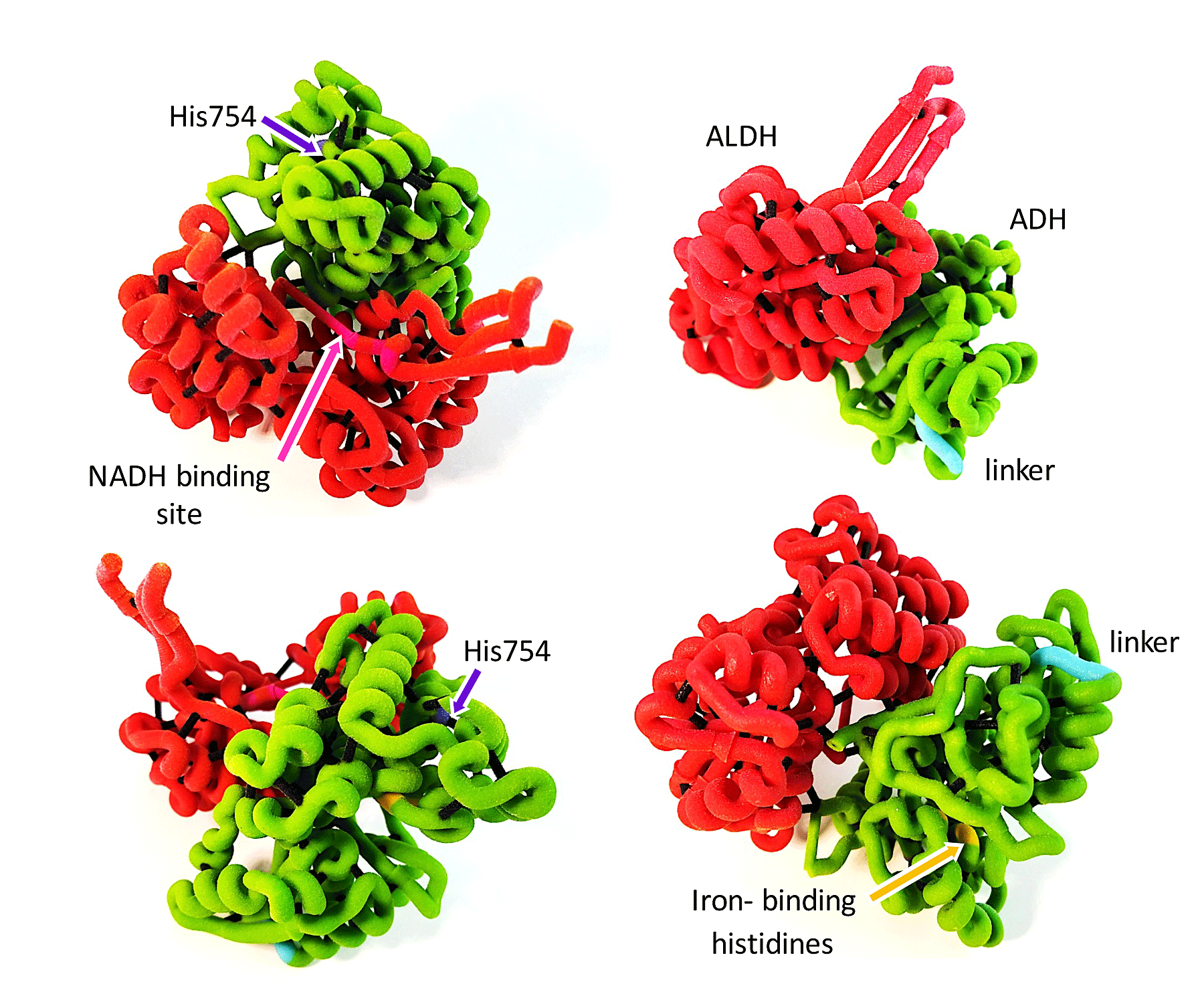
Data Sharing and Public Access Compliance Policies
All researchers who utilize INBRE resources are required to follow all INBRE and NIH policies on data sharing, data integrity and public access compliance. We have collected these resources here to help you find them more easily.
Data Management and Sharing is a critical part of the scientific process. With the rapidly growing size of scientific datasets and a desire to promote ethical and accessible data management, funding agencies and publishers are implementing increasingly strict policies on how data is archived and managed. This page will provide resources on helping you to navigate these issues.
A Data Management and Sharing Plan (DMSP or DMP) is now required for all NIH and NSF proposals. The DMP is intended to promote FAIR data practices (Findable, Accessible, Interoperable, and Reusable) which will ensure your data is reproducible and accessible. The RI-INBRE DMP applies to all RI-INBRE investigators, meaning INBRE investigators do not have to submit a separate DMP for INBRE-funded projects (same policy for COBRE and/or Advance-CTR projects). For your own proposals submitted directly to NIH or NSF, a DMP is required. We recommend using DMPTool to create your DMP. DMPTool provides an easy to use template complete with NIH-themed suggestions for completing your DMP. You may also contact Dr. Hemme for additional information on completing your DMP.
RI-INBRE_DMSP_April_2024
Resources for Data Management and Sharing


If you have any specific questions, please contact Core Director, Dr. Chris Hemme.